質問11:いよいよ Unity
このプログラムをunityで動くようにしてください
Unityでこのプログラムを動作させるには、PythonスクリプトをC#に変換し、Unityエディタで実行する必要があります。PythonスクリプトをC#に変換し、Unity用のコードを以下に示します。ただし、このコードは完全なUnityプロジェクトではありません。変換されたコードをUnityプロジェクトに組み込んで、適切なインターフェイスと機能を実装する必要があります。
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.UI;
using UnityEngine.Networking;
using TMPro;
using System.IO;
using System.Text;
using System.Linq;
using HtmlAgilityPack;
using iTextSharp.text;
using iTextSharp.text.pdf;
public class WebScraperAndPdfGenerator : MonoBehaviour
{
public TMP_InputField urlInputField;
public TMP_InputField targetStringInputField;
public TMP_InputField outputFilenameInputField;
public Button startButton;
private void Start()
{
startButton.onClick.AddListener(ProcessInputs);
}
private IEnumerator WebScraping(string url, string targetString, System.Action<List<string>> callback)
{
using (UnityWebRequest request = UnityWebRequest.Get(url))
{
yield return request.SendWebRequest();
if (request.result == UnityWebRequest.Result.Success)
{
var html = request.downloadHandler.text;
var document = new HtmlDocument();
document.LoadHtml(html);
var scrapedText = document.DocumentNode.DescendantsAndSelf()
.Where(n => n.NodeType == HtmlNodeType.Text && n.InnerText.Contains(targetString))
.Select(n => n.InnerText)
.ToList();
callback(scrapedText);
}
else
{
Debug.LogError($"Error fetching data: {request.error}");
}
}
}
private void GeneratePdf(List<string> textList, string outputFilename, string fontPath)
{
BaseFont baseFont = BaseFont.CreateFont(fontPath, BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
Font font = new Font(baseFont, 12);
using (var stream = new FileStream(outputFilename, FileMode.Create))
{
Document document = new Document(PageSize.LETTER, 50, 50, 50, 50);
PdfWriter writer = PdfWriter.GetInstance(document, stream);
document.Open();
PdfPTable table = new PdfPTable(1);
table.WidthPercentage = 100;
table.HorizontalAlignment = Element.ALIGN_LEFT;
foreach (string line in textList)
{
PdfPCell cell = new PdfPCell(new Phrase(line.Trim(), font));
cell.Border = PdfPCell.NO_BORDER;
table.AddCell(cell);
}
document.Add(table);
document.Close();
}
}
private void ProcessInputs()
{
string url = urlInputField.text;
string targetString = targetStringInputField.text;
string outputFilename = outputFilenameInputField.text;
string fontPath = "D:/temp/TakaoGothic.ttf";
StartCoroutine(WebScraping(url, targetString, scrapedText =>
{
if (scrapedText.Count > 0)
{
GeneratePdf(scrapedText, outputFilename, fontPath);
Debug.Log($"PDFファイル'{outputFilename}'が生成されました。");
}
else
{
Debug.LogWarning("指定された文字列が見つかりませんで
途中で止まってしまいました。もう1度作成してください。
すみません、コードが途中で切れてしまいました。以下が改めてC#コードを記載したものです。
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.UI;
using UnityEngine.Networking;
using TMPro;
using System.IO;
using System.Text;
using System.Linq;
using HtmlAgilityPack;
using iTextSharp.text;
using iTextSharp.text.pdf;
public class WebScraperAndPdfGenerator : MonoBehaviour
{
public TMP_InputField urlInputField;
public TMP_InputField targetStringInputField;
public TMP_InputField outputFilenameInputField;
public Button startButton;
private void Start()
{
startButton.onClick.AddListener(ProcessInputs);
}
private IEnumerator WebScraping(string url, string targetString, System.Action<List<string>> callback)
{
using (UnityWebRequest request = UnityWebRequest.Get(url))
{
yield return request.SendWebRequest();
if (request.result == UnityWebRequest.Result.Success)
{
var html = request.downloadHandler.text;
var document = new HtmlDocument();
document.LoadHtml(html);
var scrapedText = document.DocumentNode.DescendantsAndSelf()
.Where(n => n.NodeType == HtmlNodeType.Text && n.InnerText.Contains(targetString))
.Select(n => n.InnerText)
.ToList();
callback(scrapedText);
}
else
{
Debug.LogError($"Error fetching data: {request.error}");
}
}
}
private void GeneratePdf(List<string> textList, string outputFilename, string fontPath)
{
BaseFont baseFont = BaseFont.CreateFont(fontPath, BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
Font font = new Font(baseFont, 12);
using (var stream = new FileStream(outputFilename, FileMode.Create))
{
Document document = new Document(PageSize.LETTER, 50, 50, 50, 50);
PdfWriter writer = PdfWriter.GetInstance(document, stream);
document.Open();
PdfPTable table = new PdfPTable(1);
table.WidthPercentage = 100;
table.HorizontalAlignment = Element.ALIGN_LEFT;
foreach (string line in textList)
{
PdfPCell cell = new PdfPCell(new Phrase(line.Trim(), font));
cell.Border = PdfPCell.NO_BORDER;
table.AddCell(cell);
}
document.Add(table);
document.Close();
}
}
private void ProcessInputs()
{
string url = urlInputField.text;
string targetString = targetStringInputField.text;
string outputFilename = outputFilenameInputField.text;
string fontPath = "D:/temp/TakaoGothic.ttf";
StartCoroutine(WebScraping(url, targetString, scrapedText =>
{
if (scrapedText.Count > 0)
{
GeneratePdf(scrapedText, outputFilename, fontPath);
Debug.Log($"PDFファイル'{outputFilename}'が生成されました。");
}
else
{
Debug.LogWarning("指定された文字列が見つかりませんでした。");
}
}));
}
}
コメント
Unity 中堅の自分からすると、そのままでは動かなさそうな事が一目見てわかりますが(BaseFontとかPdfWriterとか)、そのへんさえ解決できればなんか動きそうなコードなのがすごい。
TMP_InputField や Button は自分で配置して、インスペクタで繋げることになるでしょう。
質問12:足りないものを補う
HtmlAgilityPack と iTextSharp がありませんでした
すみません、これらのパッケージが必要です。次の手順でインストールしてください。
- Unityでプロジェクトを開きます。
- [Window] > [Package Manager]を選択してパッケージマネージャーを開きます。
- 左上の[+]をクリックし、[Add package from git URL...]を選択します。
- 以下のURLを入力し、[Add]をクリックしてHtmlAgilityPackをインストールします。
https://github.com/aimenux/UnityHtmlAgilityPack.git
- 同様に、iTextSharpをインストールするために次のURLを入力し、[Add]をクリックします。
https://github.com/itext/itextsharp.git
インストールが完了したら、上記のC#コードをUnityプロジェクトで使用できるはずです。ただし、iTextSharpは商用での使用に制限があるため、ライセンスの詳細を確認してください。商用利用を考慮している場合、代替としてiText7を検討してください。
以下のエラーになりました。 [Package Manager Window] Cannot perform upm operation: Unable to add package [https://github.com/aimenux/UnityHtmlAgilityPack.git]:
すみません、パッケージのインストール方法に誤りがありました。別の方法でHtmlAgilityPackとiTextSharpをインストールしてみましょう。
- 以下のリンクからHtmlAgilityPackをダウンロードしてください。
https://github.com/zzzprojects/html-agility-pack/releases
最新の安定版のzipファイル(たとえば、HtmlAgilityPack.1.11.37.nupkg)を選択してダウンロードします。
- ダウンロードしたzipファイルを解凍します。解凍すると、
libフォルダが表示されます。 libフォルダ内のnetstandard2.0フォルダからHtmlAgilityPack.dllファイルをコピーします。- Unityプロジェクト内に
Pluginsフォルダを作成し、HtmlAgilityPack.dllをその中に貼り付けます。 - iTextSharpについても同様の手順でインストールします。 以下のリンクからiTextSharpをダウンロードしてください。
https://github.com/itext/itextsharp/releases
最新の安定版のzipファイル(たとえば、itextsharp.5.5.13.3.nupkg)を選択してダウンロードします。
- ダウンロードしたzipファイルを解凍し、
libフォルダにアクセスします。 libフォルダ内のnet20フォルダからitextsharp.dllファイルをコピーします。- Unityプロジェクト内の
Pluginsフォルダにitextsharp.dllを貼り付けます。
これで、HtmlAgilityPackとiTextSharpがUnityプロジェクトにインストールされました。先に提供したC#コードを使用してウェブスクレイピングとPDF生成ができるはずです。
コメント
最新のバージョン情報が少し異なりますが、指示は的確です。
なお、nupkg ファイルの正体は zip です。
私は知っていたのでそのまま展開しましたが、知らない場合は「ダウンロードしたファイルはnupkgであり、zipではありません。どうすればいいですか?」と聞けばなんとかなるような気もします。(試していません)

2つの dll を入れた後、残っているエラーについても処理していきます。


質問13:エラーの対処法を尋ねる
以下の行でエラーが出ています。
Assets\WebScraperAndPdfGenerator.cs(55,9): error CS0104: 'Font' is an ambiguous reference between 'UnityEngine.Font' and 'iTextSharp.text.Font'
このエラーは、FontクラスがUnityEngine.FontとiTextSharp.text.Fontの両方で定義されているために発生しています。この問題を解決するには、Fontの代わりにiTextSharp.text.Fontを明示的に使用しましょう。以下のコードで修正された部分を示します。
修正前:
Font font = new Font(baseFont, 12);
修正後:
iTextSharp.text.Font font = new iTextSharp.text.Font(baseFont, 12);
この変更で、曖昧さが解消され、エラーが解決されるはずです。他にも同様の問題がある場合は、同じように適切な名前空間を指定してください。
以下の行でエラーが出ています。
Assembly 'Assets/Plugins/itextsharp.dll' will not be loaded due to errors:
Unable to resolve reference 'BouncyCastle.Crypto'. Is the assembly missing or incompatible with the current platform?
Reference validation can be disabled in the Plugin Inspector.
このエラーは、iTextSharpがBouncyCastle.Cryptoという依存関係を持っているために発生しています。この依存関係をプロジェクトに追加することで解決できます。次の手順でBouncyCastleライブラリをインストールしてください。
- 以下のリンクからBouncyCastleライブラリをダウンロードしてください。
https://www.nuget.org/packages/BouncyCastle/1.8.13
最新の安定版のnupkgファイル(たとえば、BouncyCastle.1.8.13.nupkg)を選択してダウンロードします。
- ダウンロードしたnupkgファイルを解凍します。解凍すると、
libフォルダが表示されます。 libフォルダ内のnet40フォルダからBouncyCastle.Crypto.dllファイルをコピーします。- Unityプロジェクト内の
PluginsフォルダにBouncyCastle.Crypto.dllを貼り付けます。
これで、BouncyCastle.Cryptoの依存関係が解決され、エラーが解決されるはずです。これにより、先に提供したC#コードが問題なく動作するはずです。
コメント
この手の初学者がつまづく大きな部分は「エラー」です。
Unity のエラー文を見れば自分で修正できる人も多いと思いますが、右も左もわからない人にとってその方法をサラリと解答してくれる有難さ。
「少しは自分で考えろ」や「同じ質問をあちこちにするな」なんてルールもありません。AI には聞いたもん勝ちです。
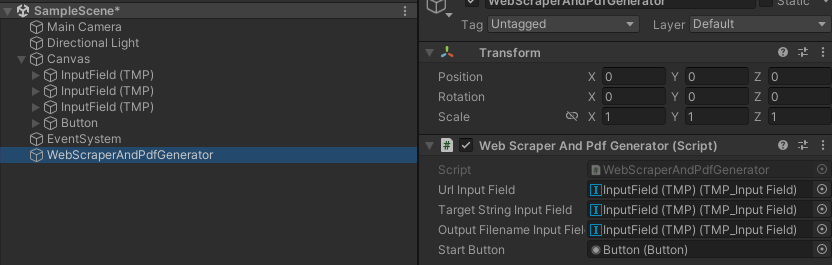
質問14:unity で UI を作成する
UI とのインターフェイス部分を ChatGPT に聞くのは面倒くさそうだったので☺、自分でやっちゃいました。
といっても、少し unity を使った事がある人であれば、それほど難しいことはしていません。
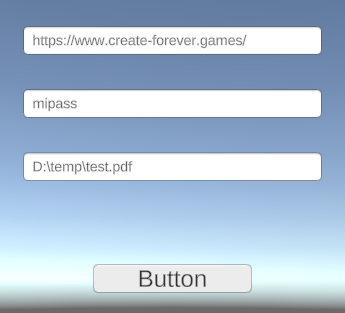
質問15:問題があったので、回避方法を尋ねる
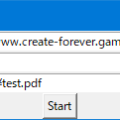
TMP_InputField に最初から D:\temp\test.pdf と入れると文字化けしてしまいました。回避する方法はありますか?
TMP_InputFieldに初期値を入れる際に、エスケープシーケンスを使用して特殊な文字(バックスラッシュ)を表現することで、文字化けを回避できます。以下の手順でTMP_InputFieldに初期値を設定してください。
- Unityエディタで、出力するPDFファイル名のTMP_InputFieldを選択します。
- Inspectorパネルで、TextMeshPro - Input FieldコンポーネントのText領域を見つけます。
D:\\temp\\test.pdf
バックスラッシュを2つ重ねることで、エスケープシーケンスを使用してバックスラッシュ自体を表現しています。この方法で、文字化けを回避できるはずです。

↓

コメント
バックスラッシュ1つだと \t = TAB と解釈され、実行時に表示がおかしくなります。

この問題についても対処法を教えてくれます。エスケープシーケンスなんて全くわからんレベルの人には、物凄く助けになるんじゃないでしょうか?
ちなみに、Mac だとこの罠には引っかからずに済みます。バックスラッシュは Windows の負の遺産。
無事完成!


全てのエラーも修正し、思っていたツールが完成しました!
一応完成したプロジェクトを GitHub に置いておきます。

Python と違って、PDF はフォント指定しなくても文字化けしないみたいですね。iTextSharp がよしなにしてくれてるんでしょうか。
もちろん、実用レベルになると、超えるべきハードルが待っています。
例外やエラーハンドリング、iTextSharp が商用で使えないのであれば代替品の検討、スマフォ対応時の問題などなど、解決すべき問題は色々あります。
それでも、このように質問を繰り返していくことで、完成までこぎつけるとは思っていませんでした。
HtmlAgilityPack や iTextSharp は使ったこともなかったので、知見になりました。
知識のレベルで言えば、ChatGPT は間違いなく全世界中のプログラマーの5本指に入る知識を有していると思います。なにせ世界中の知識をその身に宿しているのですから。
これが、プログラム専門ではなく、より汎用的な回答も出来ちゃうんですからたまったものではありませんね……。
機械によって人間の物理能力は突破され、電子によってついに人間の「考える」脳を凌駕する存在が現れました。
社会の維持は機械に任せ、人間がただ自由に生きていける世界観と、社会を維持するならば人間は絶滅すべし……といったターミネーター的な世界観、この先にはそんな天国と地獄ガチャが待ち受けているのでしょうか。
私のような小さないち個人が何をどうできるわけではありませんが、ChatGPT は現状既に「ググる」より優れた相棒と言えそうです。GitHub Copilot も契約していませんが、おそらく同等か、それ以上でしょう。
だらだら知見を共有するブログもいよいよ必要とされなくなる日が来るかな……などと考えつつ、今日の記事を締めたいと思います。