身に覚えのない大量のエラー
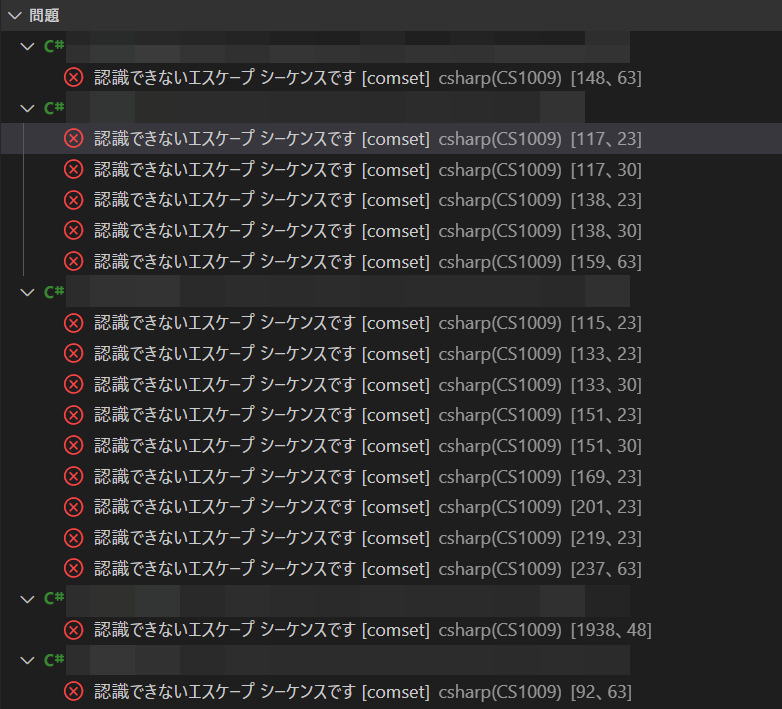
2000年くらいに作られたプロジェクトコードをワークスペースに登録したところ、このような大量のエラーが表示されました。
エラー箇所を見てみたところ…。
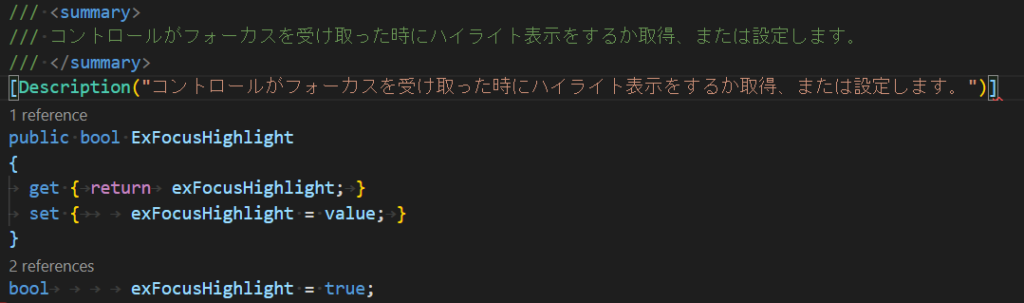
特にエスケープシーケンスしてるわけでもない。
他にも、こんな感じの単純なテーブルで構文エラーになっている。
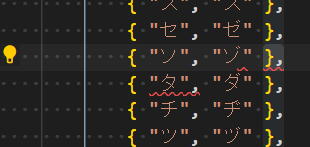
見た目には問題ないのにエラーになってる理由はなんだ…。
原因はファイルテキストのフォーマット
問題はファイルテキストのフォーマットにありました。

Shift JIS と書かれています。
これを UTF-8 で保存しなおします。Shift JIS をクリックして…。
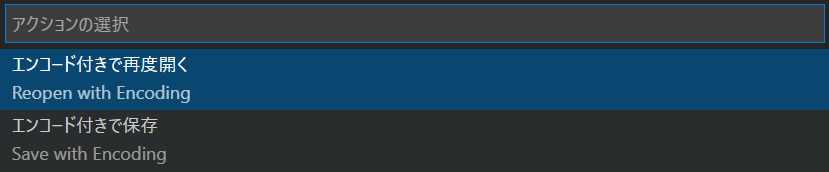
「エンコード付きで保存」を選択、UTF-8 with BOM(もしくは UTF-8)で保存します。

エラーがなくなりました!
Visual Studio ではエラーなく表示されていたので、VS Code の Shift JIS に対するロジック部分はちょっと簡素化されているというか…。
[VS Code] いや、もう Shift JIS なんてつかわんやろ!
というお気持ち表明かもしれません。
特に Shift JIS にこだわりがなければ、UTF-8 にしてしまいましょう☺
エンコーディングフォーマットの歴史
2015 年くらいからプログラマになった、なんて人は意外と知らないかもしれませんね。
そんなわけで、「把握しておくと損はない」くらいの歴史を簡単に。
適当な私見
今でこそ全て UTF-8 標準でいいよね、といった感じになっておりますが、2000 年初頭は Shift JIS 全盛だったと思います。
Shift JIS はざっくり言うと「英語と日本語の混在」のみを考慮し、ASCII コード(英数記号のみ)を上手に改造したフォーマットで、他の言語を表示することはできませんでした。
また、同時期に Unix では euc-jp という別のフォーマットも存在しました。
この違いはやがて来るインターネットという世界線で交錯し、混沌とした世界を産み出します。
データベースも、コードも、ブラウザに表示するテキストなんかも、いちいち何使ってるか意識して処理しないといけない。
本当はもっといっぱいフォーマットがあったようですが、簡単解説なので割愛。
その暗黒時代を解決しようと産まれたのが Unicode でした。当初は UTF-16 という「世界の文字は 65536 文字で収まるよね!?」という2バイト1文字のフォーマットが採択されましたが、世界はそんなに甘くはなかった。
後程、サロゲートペアなんていう「2バイト1文字…とは言っていない!」なんて状態になりました。
そこで、可変長フォーマットの UTF-8 が採用されることになりました。
UTF-8 は1文字につき最大 6 バイトなんてこともありますが、画像1枚で数百MB が当然な現在、この容量が問題視されることもないでしょう。
それに、ASCII コードについては1バイトで処理されます。
そう、半角の英数字や基本記号だけなら ASCII コードと全く一緒なのです。
この「一緒」というところが問題を引き起こすのですが…後述。
BOMあり / BOMなし
なお、Microsoft(だったと思う)は、Windows 10 くらいまでは UTF-8 を標準と認めてきませんでした。
少し前のメモ帳では ANSI と語った実体 Shift-JIS のフォーマットをデフォルトにしていましたよね。
テキストは ANSI にして! Windows のデフォルトなんだから!と言われた案件が5年前にありました😢
また、「ASCII か UTF-8 かどうか判断できないよ! 」とファイルヘッダつきの UTF-8 を好んできたことも Windows の特徴です。
このファイルヘッダがあるものを「BOMあり」、ないものを「BOMなし」といいます。
公式では…
フォーマットを策定した公式では、「BOMありも認めるけど、BOMなしが標準ね」という見解のようです。
ただ、実はBOMなしでは「ASCII文字のみ(英数字、半角記号のみ)」で構成されていると「UTF-8なのかASCIIファイルなのかわからない」という落とし穴があります。
これを利点と捉えることもできますが、以下のような問題が起こることもあるということです。

このケースではファイルに日本語をつけて対応する方法が記載されていましたが、BOM ありにすることでもおそらく対処できたでしょう。
(一番の問題は UTF-8 についての理解が足りていない納品先にありますが…)
私が携わったケースでは公文書(税務署)の電子フォーマットで、BOM ありでないと電子書類が受け付けられないという問題もありました。
そんな感じで UTF-8 と言えど、BOMあり / BOMなしについては理解しておくといいかもしれません。
トラブルを排除するにはBOMありが適切…と思うのですが、BOMありを忌み嫌う技術者もいますし、Linux で処理するツールが BOM あり未対応なんて事もあるので、ケースバイケースで対処しましょう。




